CSER 2021 Spring, hosted by Carleton University and the University of Ottawa
The event will be online from 9 a.m. to 5:30 (Eastern time) on May 14th. Click on the Registration link at the left to find out how to register, and click on the Program link to see the program.
The first CSER meeting was in 1996, so 2021 is the 25th anniversary!
Over 235 people are registered, from 9 Canadian provinces, 5 other countries, amd 45 universities and colleges.
CSER meetings seek to motivate engaging discussions among faculty, graduate students and industry participants about software engineering research in a broad sense, as well as the intersection between software engineering, other areas of computer science, and other disciplines.

Slides of Lionel's Presentation
Abstract: There is a long history of applications of various Artificial Intelligence (AI) technologies in software engineering. From machine learning, evolutionary computing, to Natural Language Processing, AI has played an increasingly important role in making software engineering more predictable and automatable. This rising impact stems from increasingly powerful AI technologies, easy access to enormous computing power, and the availability of large amounts of software data in readily available development repositories. This talk will provide a reflection over 25 years of experience in applying and tailoring AI techniques to address software engineering problems at scale. Recent developments and future research directions will also be outlined.
Bio: Lionel C. Briand is professor of software engineering and has shared appointments between (1) The University of Ottawa, Canada and (2) The SnT centre for Security, Reliability, and Trust, University of Luxembourg. Lionel was elevated to the grades of IEEE Fellow and ACM Fellow. He was the recipient of the IEEE CS Harlan Mills award in 2012 and also received an ERC Advanced grant in 2016. More recently, he was awarded a Canada Research Chair (Tier 1) on “Intelligent Software Dependability and Compliance”. His research interests include: software testing and verification, model-driven software development, applications of AI in software engineering, and empirical software engineering.
Twitter: @lionel_c_briand / Lionel Briand's Website

Abstract:The benefit of using evidence-based teaching practices to improve student learning outcomes has been well-documented. Sometimes, however, the best practices are not obvious or easy to use. Implementation science is an empirical approach to bridging the gap between research and practice that has been used to move effective teaching practices rapidly from research publications to the classroom. A data-driven approach can also help us understand why important practices like artifact sharing can be frustrating or ineffective. Recent research has identified high-level challenges that affect the quality, sharing, and success of software engineering artifacts, and enables us to capitalize on opportunities to improve the quality of artifacts in the future. This talk will address data-driven approaches to improving your teaching, and to improving the quality of software engineering artifacts for the community as a whole.
Bio: Dr. Lauren Herckis is a Carnegie Mellon University anthropologist specializing in faculty culture and the use of technology in higher education. She is appointed in Carnegie Mellon’s Dietrich College of Humanities & Social Sciences, Human-Computer Interaction Institute, Simon Initiative, and Block Center for Technology and Society. Her research explores the ways that people engage with innovative technologies, how innovation shapes culture, the potential of virtual and augmented reality “spaces” to function as meaningful social places, and how social networks dynamically impact technical choices and the development of informal economies. Current projects examine the intersection of campus culture, technological change, and effective teaching. A Fulbright recipient, Dr. Herckis’ work has also been funded by the National Science Foundation, the Carnegie Corporation of New York, the Chan Zuckerberg Initiative, California Education Learning Lab, and the Hillman Family Foundations. Today, her research informs policymaking, shapes the development of learning technologies, and illuminates aspects of organizational culture and policy that affect teaching in colleges and universities around the world.
Twitter: @laurenindafield
9 a.m. Introduction and Keynote by Lionel Briand
10 a.m. Break 1
10:10 a.m. Session A Human Aspects part 1 (Main channel) and Session B Data Mining and Machine Learning in SE part 1 (Breakout)
10:54 a.m. Break 2
11:04 a.m. Session C Human Aspects part 2 (Main channel) and Session D Data Mining and Machine Learning in SE part 2 (Breakout)
12:11 a.m. Lunch
1:06 p.m. Session E Dependencies, Building, Packaging and DevOps (Main channel) and Session F Frontiers and Other Topics (Breakout)
2:49 p.m. Break 3
3 p.m. Keynote by Lauren Herckis
3:49 p.m. Break 4
3:59 p.m. Session G Performance and Dynamic Analysis (Main channel) and Session H Program Comprehension and Analysis (Breakout)
5:19 p.m. Final plenary
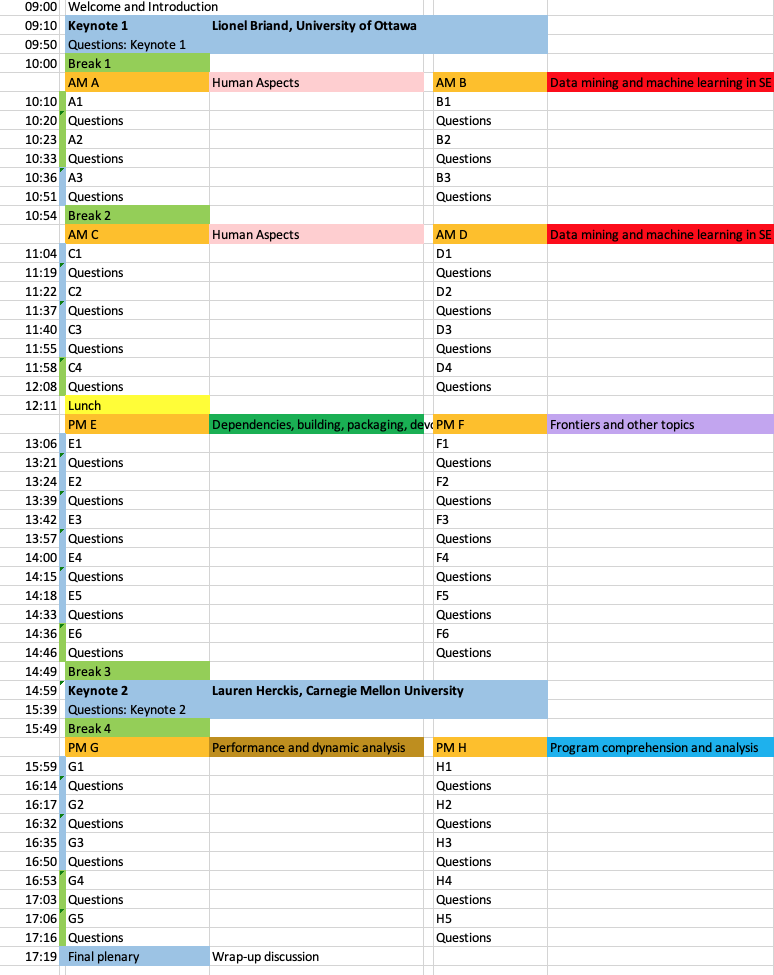
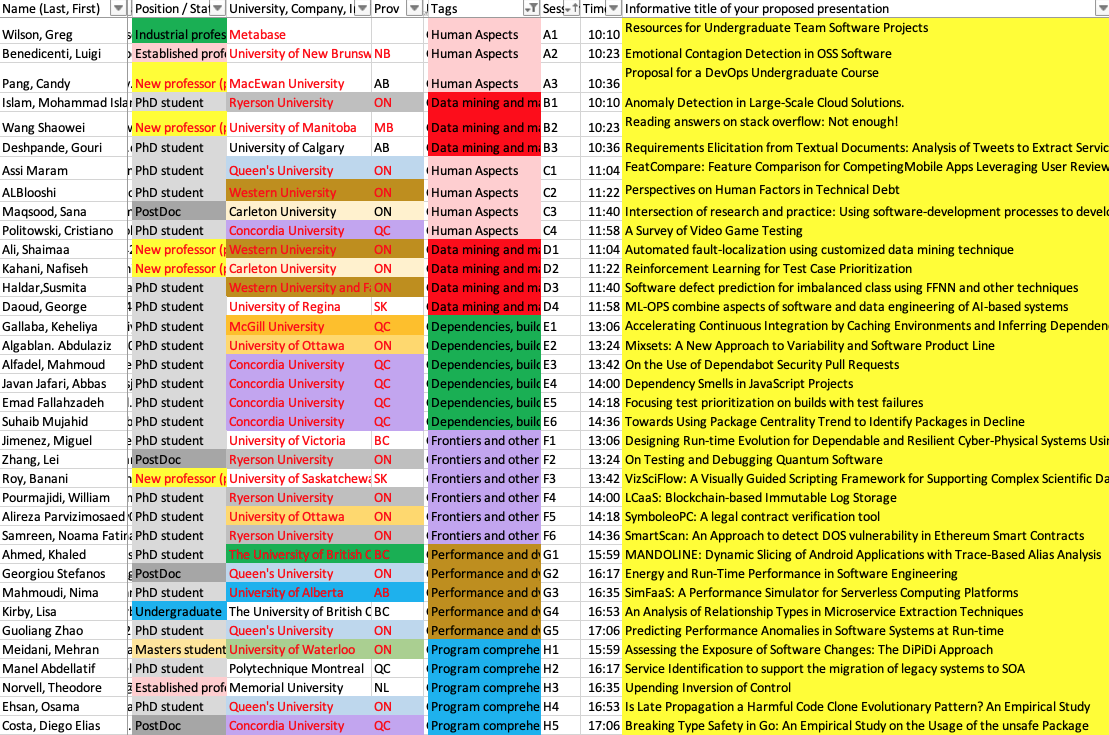
Sessions B, D, F and H will be in a breakout room, and attendees will be able to go back and forth from room to room). We will assign two people presenting in the same or a related session to lead the question answering for every paper.
Software Tools in JavaScript (https://stjs.tech/) and Building Software Together (https://buildtogether.tech/) are two new open-access resources intended for use in undergraduate software engineering projects. This brief presentation will describe them and explore ways they can be used. (More information about the topic) .
More information about the author
Can we influence the mood and productivity of other developers simply through messages? This presentation will cover a method to determine if such influence can occur in distributed online developer communities focused on open source software. .
More information about the author
DevOps (Development-Operations) is a popular topic in the IT industry. There is a high demand of DevOps Engineers. Many of our graduated students asked us why they have not learned about DevOps in their degree program. I have studied about DevOps education. There are many challenges in providing DevOps education. One of the challenges is that the scope of DevOps is expanding rapidly, which includes continuous integration (CI), continuous delivery (CD), site reliability engineering (SRE), and many more [4]. Just CI alone, multiplies into six continuous processes: (1) Continuous Code Integration, (2) Continuous Database Integration, (3) Continuous Testing, (4) Continuous Inspection, (5) Continuous Delivery, (6) Continuous Feedback. Therefore, defining DevOps curriculum is like shooting a fast-moving target. I reviewed the limited number of existing DevOps curriculums, the focuses are on tools which support different CI processes (e.g. automated testing tools). However, there are a large number of DevOps tools, and tools may not sustain. Therefore, I purpose teaching the rationale behind DevOps, instead of teaching DevOps tools. Give a man a fish and you feed him for a day. Teach a man to fish and you feed him for a lifetime. Students who understand the rationale behind DevOps can find the right tools for the right tasks. I would like to share my proposal of an undergraduate DevOps course. So that I can gather feedback and suggestions from the experienced software engineering educators about the course's learning objectives, format, schedule, assignments, and teaching material. .
More information about the author
In this talk, we will be highlighting various aspects of Anomaly Detection in Cloud Platforms. Cloud computing is everywhere: the rise in popularity challenges Cloud service providers, as they need to monitor the quality of their ever-growing offerings effectively. To address the challenge, we designed and implemented an automated monitoring system for the IBM Cloud Platform. This monitoring system utilizes deep learning neural networks to detect anomalies in near-real-time in multiple Platform components simultaneously. The proposed solution frees the DevOps team’s time and human resources from manually monitoring thousands of Cloud components. Moreover, it increases customer satisfaction by reducing the risk of Cloud outages. This paper shares our solutions’ architecture, implementation notes, and best practices that emerged while evolving the monitoring system. Other researchers and practitioners can leverage the architecture, implementation notes, and best practices of our solutions to build anomaly detectors for complex systems in different domains. .
More information about the author
Stack Overflow is one of the most active communities for developers to share their programming knowledge. Answers posted on Stack Overflow help developers solve issues during software development. In addition to posting answers, users can also post comments to further discuss their associated answers. As of Aug 2017, there are 32.3 million comments that are associated with answers, forming a large collection of crowdsourced repository of knowledge on top of the commonly-studied Stack Overflow answers. In this study, we wish to understand how the commenting activities contribute to the crowdsourced knowledge. We investigate what users discuss in comments, and analyze the characteristics of the commenting dynamics, (i.e., the timing of commenting activities and the roles of commenters). We find that: 1) the majority of comments are informative and thus can enhance their associated answers from a diverse range of perspectives. However, some comments contain content that is discouraged by Stack Overflow. 2) The majority of commenting activities occur after the acceptance of an answer. More than half of the comments are fast responses occurring within one day of the creation of an answer, while later comments tend to be more informative. Most comments are rarely integrated back into their associated answers, even though such comments are informative. 3) Insiders (i.e., users who posted questions/answers before posting a comment in a question thread) post the majority of comments within one month, and outsiders (i.e., users who never posted any question/answer before posting a comment) post the majority of comments after one month. Inexperienced users tend to raise limitations and concerns while experienced users tend to enhance the answer through commenting. Our study provides insights into the commenting activities in terms of their content, timing, and the individuals who perform the commenting. For the purpose of long-term knowledge maintenance and effective information retrieval for developers, we also provide actionable suggestions to encourage Stack Overflow users/engineers/moderators to leverage our insights for enhancing the current Stack Overflow commenting system for improving the maintenance and organization of the crowdsourced knowledge. .
More information about the author
Before the COVID-19 pandemic, the City of Calgary municipal organization faced financial pressures due to the aftermath of the 2015 oil price collapse. COVID-19 pandemic has further amplified the challenge and urgency to identify citizens' needs correctly and promptly to channelize the funds in enhancing services efficiently. Critical services, such as emergency response, healthcare, and public transportation could be then identified and prioritized for maximal benefit. However, the challenge is that the services needs are incremental and evolving continuously. For example, emergency response and public transport were critical until health care took the lead due to the ongoing pandemic. Interestingly need for health care service was high during the first wave than that of the second wave. Since requirements elicitation is a processing of seeking, identifying and acquiring requirements for computer-based systems, through this research design we envision to provide a novel Decision-Support System (DSS) that will identify and facilitate the critical services needs and provide decision support for effective and incremental delivery of these services. As such, the decision will be driven by data analytics on real-time data mined from social media platforms such as Twitter. In a nutshell, this DSS tool will transform massive textual content into gold nuggets - meaningful summaries - utilizing state-of-the-art Natural Language processing (NLP) and Machine learning (ML) techniques. Firstly, using NLP, unwanted tweets (sift the wheat from the chaff) are identified and eliminated and then using ML, tweets are clustered to identify potential services. Finally, using advanced NLP techniques, clusters are aggregated and presented as summaries for each service to decision-makers. This DSS could aid in effective service portfolio management with reduced efforts. .
More information about the author
Given the competitive mobile app market, developers must be fully aware of users’ needs, satisfy users’ requirements, combat apps of similar functionalities (i.e.,competing apps), and thus stay ahead of the competition. While it is easy to track the overall user ratings of competing apps, such information fails to provide actionable insights for developers to improve their apps over the competing apps. Thus, developers still need to read reviews from all their interested competing apps and summarize the advantages and disadvantages of each app. Such a manual process can be tedious and even infeasible with thousands of reviews posted daily.To help developers compare users’ opinions among competing apps onhigh-level features, such as the main functionalities and the main characteristics of an app, we propose a review analysis approach named FeatCompare. Feat-Compare can automatically identify high-level features mentioned in user reviews without any manually annotated resource. Then, FeatCompare creates a comparative table that summarizes users’ opinions for each identified feature across competing apps. FeatCompare features a novel neural network-based model named Global-Local sensitive Feature Extractor (GLFE), which extends Attention-based Aspect Extraction (ABAE), a state-of-the-art model for extracting high-level features from reviews. We evaluate the effectiveness of GLFE on 480 manually annotated reviews sampled from five groups of competing apps. Our experiment results show that GLFE achieves a precision of 79%-82% and recall of 74%-77% in identifying the high-level features associated with reviews and outperforms ABAE by 14.7% on average. We also conduct a case study to demonstrate the usage scenarios of FeatCompare. A survey with 107 mobile app developers shows that more than 70% of developers agree that FeatCompare is of great benefit. .
More information about the author
Software development activities are carried out by individuals with varying personalities and characteristics that govern their actions and decisions. These actions and decisions impact the success and quality of the software product. Technical debt is a byproduct of some decisions taken under certain circumstances to achieve immediate objectives of product development and release. Therefore, it is worthwhile to gain an insight on human factors affecting the TD management process and exploring strategic management approaches in controlling TD. .
The majority of tweens – 10 to 13 year old children – have experienced some form of online risk, such as cyberbullying, misinformation, and reputational risk. Thus, we need to design educational tools to help them understand these risks, and empower them to make safe and privacy preserving choices online, as they transition into adolescence and begin using more digital media. Given this, in collaboration with MediaSmarts – a Canadian not-for-profit charitable organization which promotes digital literacy – we designed, developed, evaluated, and deployed a digital literacy game for 11-13 year-olds (A Day in the Life of the JOs), which is now being used in over 300 Canadian elementary schools. In this talk, I will discuss our design-based research process of designing the game, and the realities of completing a real-world software-development project, while balancing research goals and the requirements of a non-academic partner. (More information about the topic> .
More information about the author
Video-game projects are notorious for having day-one bugs, no matter how big their budget or team size. The quality of a game is essential for its success. This quality could be assessed and ensured through testing. However, to the best of our knowledge, little is known about video-game testing. In this paper, we want to understand how game developers perform game testing. We investigate, through a survey, the academic and gray literature to identify and report on existing testing processes and how they could automate them. We found that game developers rely, almost exclusively, upon manual play-testing and the testers' intrinsic knowledge. We conclude that current testing processes fall short because of their lack of automation, which seems to be the natural next step to improve the quality of games while maintaining costs. However, the current game-testing techniques may not generalize to different types of games. (More information about the topic> .
More information about the author
Software fault localization is one of the major bottle necks in the software development industry. In this presentation we’ll discuss a process for collecting particular behavior traces from the subject program and analyzing them using a customized data mining technique in order to produce a list of classes that are suspected contain the fault. .
More information about the author
Continuous Integration (CI) significantly reduces integration problems, speeds up software development time, and shortens release time. However, it also introduces new challenges for quality assurance activities, including regression testing. Though various approaches for test case prioritization have shown to be promising in the context of regression testing, specific techniques must be designed to deal with the dynamic nature and timing constraints of CI. Recently, Reinforcement Learning (RL) has shown great potential in various challenging scenarios that require continuous adaptation, such as game playing, and recommender systems. Inspired by this line of work and building on initial efforts in supporting test case prioritization with RL techniques, we perform a comprehensive investigation of RL-based test case prioritization in a CI context. Our extensive experimental analysis shows that the best RL solutions provide a significant accuracy improvement over previous RL-based work, thus paving the way for using RL to prioritize test cases in a CI context. .
More information about the author
Finding the relationship between static code measure metrics and probability of defect detection in a software artifact is an ongoing research area in Software Engineering domain. In this paper, I will present a case study of supervised learning techniques in defect prediction based on a publicly available dataset provided by NASA. Multiple techniques including FFNN were used. During the analysis, it was observed that the dataset is facing class imbalance problem. As a result, various data preprocessing techniques such as under sampling, oversampling, SMOTE were used to overcome this issue. In addition, comparison of SDP model performance was captured based on obtained model by without applying SMOTE and with applying SMOTE to see the impact on the dataset. The software defect prediction (SDP) model was tested with Naïve Bayes Classifiers, Logistic Regression, Random Forest model, Support Vector Machines, and finally with Feed Forward Neural Networks. Since the performance of SMOTE outweigh the other data processing approach, this result has been presented in this paper. (More information about the topic> .
More information about the author
We report on using ML-OPS to develop ML models. MLOPS is used to continuously integrate data, retrain models and convert them into deployable services. The services are used in different business workflows to control and optimize operations. We discuss this in the context of predicting and optimizing production performance of oil reservoirs. Such prediction involves sophisticated non-uniqueness problems. Current practices involve running thousands of heavy-weight numerical reservoir simulations to provide accurate results. ML models are used as a substitute for these complex simulations. ML models are much faster and require lesser computing resources. However, the training of such models is very complex considering various neural network architectures (e.g., RNN, LSTM, CNN), stringent result-validation requirements and the many different inter-disciplinary (geology, petrophysics, production, and drilling) input parameters. In this presentation, we explain how MLOPS can be used for engineering required data to build the ML models as well as to continuously integrate (CI) data, retrain models (CT) and deploy services (CD). .
To facilitate the rapid release cadence of modern software (on the order of weeks, days, or even hours), software development organizations invest in practices like Continuous Integration (CI), where each change submitted by developers is built (e.g., compiled, tested, linted) to detect problematic changes early. A fast and efficient build process is crucial to provide timely CI feedback to developers. If CI feedback is too slow, developers may switch contexts to other tasks, which is known to be a costly operation for knowledge workers. Thus, minimizing the build execution time for CI services is an important task. While recent work has made several important advances in the acceleration of CI builds, optimizations often depend upon explicitly defined build dependency graphs (e.g., make, Gradle, CloudBuild, Bazel). These hand-maintained graphs may be (a) underspecified, leading to incorrect build behaviour; or (b) overspecified, leading to missed acceleration opportunities. In this paper, we propose Kotinos—a language-agnostic approach to infer data from which build acceleration decisions can be made without relying upon build specifications. After inferring this data, our approach accelerates CI builds by caching the build environment and skipping unaffected build steps. Kotinos is at the core of a commercial CI service with a growing customer base. To evaluate Kotinos, we mine 14,364 historical CI build records spanning three proprietary and seven open-source software projects. We find that: (1) at least 87.9% of the builds activate at least one Kotinos acceleration; and (2) 74% of accelerated builds achieve a speed-up of two-fold with respect to their non-accelerated counterparts. Moreover, (3) the benefits of Kotinos can also be replicated in open source software systems; and (4) Kotinos imposes minimal resource overhead (i.e., < 1% median CPU usage, 2 MB – 2.2 GB median memory usage, and 0.4 GB – 5.2 GB median storage overhead) and does not compromise build outcomes. Our results suggest that migration to Kotinos yields substantial benefits with minimal investment of effort (e.g., no migration of build systems is necessary). (More information about the topic> .
More information about the author
The concept of mixsets is introduced in Umple as a conditional unit and a first-class entity to allow a smooth transition from singular software to compositional SPLs. A mixset is a named set of mixins; each mixin belonging to the mixset is called a fragment. A mixset fragment can be a top-level entity that contains nested entities or can be embedded as a conditional fragment in other entities such as class methods. Require statements can be specified to describe explicit dependencies among mixsets. Mixsets can be used to specify product lines using code composition, code annotation or both. A strength of mixsets lies on the straightforward mechanism to transform annotated segments into compositional segments when used in a combined approach. Therefore, effort and time to transform annotative SPLs to compositional SPLs can be reduced. Mixsets can provide a backbone structure to realize product line features in a feature-based SPL. Hence, a feature model can be formed using a subset of specific dependent mixsets. Feature interactions within an SPL can be identified and separated in specific modules by mixset nesting. Furthermore, product configuration, feature modeling analysis and generation of feature diagrams can be accomplished based on mixsets. We demonstrate a method to enable the granularity of compositional approaches to be expressed at the statement-level. This is achieved by allowing aspects to inject code into labelled places, or points of variation, within method code. Such injected code has a full access to the context in which its placed, such as access to local variables. Mixsets are implemented in Umple, a model-driven development (MDD) technology that allows combining abstract models, such as associations and state machines, with pure code, and generating code in multiple programming languages. Mixsets can thus be used to described variations in models, not just code. Evaluation is by case studies, including applying mixsets to the Oracle Berkeley Database SPL, which is used in other literature to evaluate SPL concepts. The case study shows that the mixset implementation improves on the state of the art in several respects, such as elimination of complex workarounds that are required by other approaches. (More information about the topic> .
Vulnerable dependencies are a major problem in modern software development. As software projects depend on multiple external dependencies, developers struggle to constantly track and check for corresponding security vulnerabilities that affect their project dependencies. To help mitigate this issue, Dependabot has been created, a bot that issues pull-requests to automatically update vulnerable dependencies. However, little is known about the degree to which developers adopt Dependabot to help them update vulnerable dependencies. In this paper, we investigate 2,904 JavaScript open-source GitHub projects that subscribed to Dependabot. Our results show that the vast majority (65.42%) of the created security-related pull-requests are accepted, often merged within a day. Through manual analysis, we identify 7 main reasons for Dependabot security pull-requests not being merged, mostly related to concurrent modifications of the affected dependencies rather than Dependabot failures. Interestingly, only 3.2% of the manually examined pull-requests suffered from build breakages. Finally, we model the time it takes to merge a Dependabot security pull-request using characteristics from projects, the fixed vulnerabilities and issued pull requests. Our model reveals 5 significant features to explain merge times, e.g., projects with relevant experience with Dependabot security pull-requests are most likely associated with rapid merges. Surprisingly, the severity of the dependency vulnerability and the potential risk of breaking changes are not strongly associated with the merge time. To the best of our knowledge, this study is the first to evaluate how developers receive Dependabot’s security contributions. Our findings indicate that Dependabot provides an effective platform for increasing awareness of dependency vulnerabilities and helps developers mitigate vulnerability threats in JavaScript projects. (More information about the topic> .
More information about the author
Dependency management in modern software development poses many challenges for developers who wish to stay up to date with the latest features and fixes whilst ensuring backwards compatibility. Project maintainers have opted for varied, and sometimes conflicting, approaches for maintaining their dependencies. Opting for unsuitable approaches can introduce bugs and vulnerabilities into the project, introduce breaking changes, cause extraneous installations, and reduce dependency understandability, making it harder for others to contribute effectively. In this talk, we empirically examine evidence of recurring dependency management issues (dependency smells). We look at the commit data for 1,146 active JavaScript repositories to catalog, quantify and understand dependency smells. Through a series of surveys with practitioners, we identify and quantify seven dependency smells with varying degrees of popularity and investigate why they are introduced throughout project history. Our findings indicate that dependency smells are prevalent in JavaScript projects and the number of dependency smells tend to increase over time. Practitioners agree that dependency smells bring about many problems including security threats, bugs, dependency breakage, runtime errors, and other maintenance issues. These smells are generally introduced as developers react to dependency misbehaviour and the shortcomings of the npm ecosystem. (More information about the topic> .
More information about the author
The software codebases of large companies are constantly growing, and by using a continuous integration development process they require every change to be tested. This increases the number of tests and the time consumed for accomplishing tests and it delays the software release. In the rapid release environment, this is a significant bottleneck. Consequently, many studies tried to alleviate the problem by giving developers faster feedback about failing tests. They conduct it by prioritizing the tests in a way that the probability of detecting the failing tests would increase. In this work, we undertake the hypothesis that bugs might cluster, and one failing test might be a clue that leads us to more failing tests. We implement the BatchedFifo algorithm as the baseline for our comparisons, and the DynaQFocus and DynaQFocusFail algorithms based on our hypothesis. We also evaluate their performance in comparison with the GoogleTCP algorithm against the Google and Chrome data sets. Our experiments reveal the fact that the focus idea is not necessarily true. As we do a deeper investigation on the results and the data sets under evaluation we find out that most of the builds consist only a few numbers of failing tests, and this feature is against our earlier hypothesis. The lessons we have learned from this study can help future works. .
Due to its increasing complexity, today's software systems are frequently built by leveraging reusable code in the form of libraries and packages. Software ecosystems (e.g., npm) are the primary enablers of this code reuse, providing developers with a platform to share their own and use others' code. These ecosystems evolve rapidly: developers add new packages every day to solve new problems or provide alternative solutions, causing obsolete packages to decline in their importance to the community. Developers should avoid depending on packages in decline, as these packages are reused less over time and may become less frequently maintained. However, current popularity metrics are not fit to provide this information to developers. In this paper, we propose a scalable approach that uses the package's centrality in the ecosystem to identify packages in decline. We evaluate our approach with the npm ecosystem and show that the trends of centrality overtime can correctly distinguish packages in decline with an ROC-AUC of 0.9. The approach can capture 87% of the packages in decline, on average 18 months before the trend is shown in currently used package popularity metrics. We implement this approach in a tool that can be used to augment npms metrics and help developers avoid packages in decline when reusing packages from npm. (More information about the topic> .
More information about the author
The proliferation of Smart Cyber-Physical Systems (SCPS) is increasingly blurring the boundaries between physical and virtual entities. This trend is revolutionizing multiple application domains along the whole human activity spectrum, while pushing the growth of new businesses and innovations such as smart manufacturing, cities and transportation systems, as well as personalized healthcare. Technological advances in the Internet of Things, Big Data, Cloud Computing and Artificial Intelligence have effected tremendous progress toward the autonomic control of SCPS operations. However, the inherently dynamic nature of physical environments challenges SCPS’ ability to perform adequate control actions over managed physical assets in myriad of contexts. From a design perspective, this issue is related to the system states of operation that cannot be predicted entirely at design time, and the consequential need to define adequate capabilities for run-time self-adaptation and self-evolution. Nevertheless, adaptation and evolution actions must be assessed before realizing them in the managed system in order to ensure resiliency while minimizing the risks. Therefore, the design of SCPS must address not only dependable autonomy but also operational resiliency. In light of this, the contribution of this talk is threefold. First, we present a reference architecture for designing dependable and resilient SCPS that integrates concepts from the research areas of Digital Twin, Adaptive Control and Autonomic Computing. Second, we present a model identification mechanism for guiding self-evolution, based on continuous experimentation, evolutionary optimization and dynamic simulation, as the architecture’s first major component for dependable autonomy. Third, we present an adjustment mechanism for self-adaptation, based on gradient descent, as the architecture’s second major component, addressing operational resiliency. Our contributions aim to further advance the research of reliable self-adaptation and self-evolution mechanisms and their inclusion in the design of SCPS. .
Quantum computers are becoming more mainstream. As more programmers are starting to look at writing quantum programs, they need to test and debug their code. In this talk, we will cover some fundamentals of quantum computing and discuss various testing and debugging tactics that one can leverage to ensure the quality of the quantum software. The practitioners can readily apply some of these tactics to the process of writing quantum programs, while researchers can learn about opportunities for future work. (More information about the topic> .
More information about the author
Scientific workflow management systems such as Galaxy, Taverna and Workspace, have been developed to automate scientific workflow management and are increasingly being used to accelerate the specification, execution, visualization, and monitoring of data-intensive tasks. For example, the popular bioinformatics platform Galaxy is installed on over 168 servers around the world and the social networking space myExperiment shares almost 4,000 Galaxy scientific workflows among its 10,665 members. Most of these systems offer graphical interfaces for composing workflows. However, while graphical languages are considered easier to use, graphical workflow models are more difficult to comprehend and maintain as they become larger and more complex. Text-based languages are considered harder to use but have the potential to provide a clean and concise expression of workflow even for large and complex workflows. A recent study showed that some scientists prefer script/text-based environments to perform complex scientific analysis with workflows. Unfortunately, such environments are unable to meet the needs of scientists who prefer graphical workflows. In order to address the needs of both types of scientists and at the same time to have script-based workflow models because of their underlying benefits, we propose a visually guided workflow modeling framework that combines interactive graphical user interface elements in an integrated development environment with the power of a domain-specific language to compose independently developed and loosely coupled services into workflows. Our domain-specific language provides scientists with a clean, concise, and abstract view of workflow to better support workflow modeling. As a proof of concept, we developed VizSciFlow, a generalized scientific workflow management system that can be customized for use in a variety of scientific domains. As a first use case, we configured and customized VizSciFlow for the bioinformatics domain. We conducted three user studies to assess its usability, expressiveness, efficiency, and flexibility. Results are promising, and in particular, our user studies show that VizSciFlow is more desirable for users to use than either Python or Galaxy for solving complex scientific problems. (More information about the topic> .
More information about the author
During the normal operation of a Cloud solution, no one pays attention to the logs except the system reliability engineers, who may periodically check them to ensure that the Cloud platform’s performance conforms to the Service Level Agreements (SLA). However, the moment a component fails, or a customer complains about a breach of SLA, the importance of logs increases significantly. All departments, including management, customer support, and even the actual customer, may turn to logs to determine the cause and timeline of the issue and to find the party responsible for the issue. The party at fault may be motivated to tamper with the logs to hide their role. Given the number and volume of logs generated by the Cloud platforms, many tampering opportunities exist. We argue that the critical nature of logs calls for immutability and verification mechanisms without the presence of a single trusted party. In this talk, we propose such a mechanism by describing a blockchain-based log system, called Logchain, which can be integrated with existing private and public blockchain solutions. Logchain uses the immutability feature of blockchain to provide a tamper-resistance storage platform for log storage. Additionally, we propose a hierarchical structure to combine the hash-binding of two blockchains to address blockchains’ scalability issues. To validate the mechanism, we integrate Logchain into two different types of blockchains. We choose Ethereum as a public, permission-less blockchain and IBM Blockchain as a private, permission-based one. We show that the solution is scalable on both the private and public blockchains. Additionally, we perform the analysis of the cost of ownership for private and public blockchains implementations to help practitioners select an implementation that would be applicable to their needs. (More information about the topic> .
More information about the author
Legal contracts specify the terms and conditions – in essence, requirements – that apply to business transactions. Contracts may contain errors and violate properties desired by the parties involved. Symboleo was recently developed as a formal specification language for legal contracts. We proposed a formal specification language for legal contracts, called Symboleo, where contracts consist of collections of obligations and powers that define a legal contract’s compliant executions. Regarding the Symbleo, we developed a tool, called SymboleoPC, that can prove desired properties of a contract, expressed in temporal logic, or find counterexamples. The performance and scalability of the tool has been assessed with respect to the size of contracts and properties to be checked through a series of experiments. The results suggest that SymboleoPC can be usefully applied to the analysis of formal specifications of real-life contracts. (More information about the topic> .
Blockchain technology’s (BT) Ethereum Smart Contracts allows programmable transactions that involve the transfer of financial assets among peers on a BT network independent of a central authorizing agency. Ethereum Smart Contracts are programs that are deployed as decentralized applications, having the building blocks of the blockchain consensus protocol. This technology enables consumers to make agreements in a transparent and conflict-free environment. However, the security vulnerabilities within these smart contracts are a potential threat to the applications and their consumers and have shown in the past to cause huge financial losses. In this paper, we propose a framework that combines static and dynamic analysis to detect Denial of Service (DoS) vulnerability due to an unexpected revert in Ethereum Smart Contracts. Our framework, SmartScan, statically scans smart contracts under test (SCUTs) to identify patterns that are potentially vulnerable in these SCUTs and then uses dynamic analysis to precisely confirm the exploitability of the DoS-Unexpected Revert vulnerability, thus achieving increased performance and precise results. We evaluated SmartScan on a dataset of 500 smart contracts collected from the Etherscan web portal. Our approach shows an improvement in precision and recall when compared to the available state of the art techniques. (More information about the topic> .
More information about the author
Dynamic program slicing is used in a variety of tasks, including program debugging and security analysis. Build- ing an efficient and effective dynamic slicing tool is a challenging task, especially in an Android environment, where programs are event-driven, asynchronous, and interleave code written by a developer with the code of the underlying Android platform. The user-facing nature of Android applications further complicates matters as the slicing solution has to maintain a low overhead to avoid substantial application slowdown. In this presentation, I will present my work on proposing an accurate and efficient dynamic slicing technique for Android applications and implement it in a tool named MANDOLINE. The core idea behind our technique is to use minimal, low-overhead instrumentation followed by sophisticated, on-demand execution trace analysis for constructing a dynamic slice. We also contribute a benchmark suite of Android applications with manually constructed dynamic slices that use a faulty line of code as a slicing criterion. We evaluate MANDOLINE on that benchmark suite and show that it is substantially more accurate and efficient than the state-of-the-art dynamic slicing technique named ANDROIDSLICER (More information about the topic> .
More information about the author
Energy efficiency for computer systems is an ever-growing matter that has caught the attention of the software engineering community. Although hardware design and utilization are undoubtedly key factors affecting energy consumption, there is solid evidence that software design can also significantly alter the energy consumption of IT products. Therefore, the goal of this presentation is to show the impact of software design decisions on the energy consumption of a computer system. First, this presentation aims to point out which programming languages can introduce better energy and run-time performance for specific programming tasks and computer platforms (i.e., server, laptop, and embedded system). Later on, different programming languages and computer platforms are used to demonstrate the energy and delay implications of various inter-process communication technologies (i.e, REST, RPC, gRPC) that are used on daily basis from various web services. In conclusion, many factors that can affect the energy and run-time performance of applications. However, pointing them out is a challenge and further research is required. (More information about the topic> .
More information about the author
Developing accurate and extendable performance models for serverless platforms, aka Function-as-a-Service (FaaS) platforms, is a very challenging task. Also, implementation and experimentation on real serverless platforms is both costly and time-consuming. However, at the moment, there is no comprehensive simulation tool or framework to be used instead of the real platform. As a result, in this paper, we fill this gap by proposing a simulation platform, called SimFaaS, which assists serverless application developers to develop optimized Function-as-a-Service applications in terms of cost and performance. On the other hand, SimFaaS can be leveraged by FaaS providers to tailor their platforms to be workload-aware so that they can increase profit and quality of service at the same time. Also, serverless platform providers can evaluate new designs, implementations, and deployments on SimFaaS in a timely and cost-efficient manner. SimFaaS is open-source, well-documented, and publicly available, making it easily usable and extendable to incorporate more use case scenarios in the future. Besides, it provides performance engineers with a set of tools that can calculate several characteristics of serverless platform internal states, which is otherwise hard (mostly impossible) to extract from real platforms. In previous studies, temporal and steady-state performance models for serverless computing platforms have been developed. However, those models are limited to Markovian processes. We designed SimFaaS as a tool that can help overcome such limitations for performance and cost prediction in serverless computing. We show how SimFaaS facilitates the prediction of essential performance metrics such as average response time, probability of cold start, and the average number of instances reflecting the infrastructure cost incurred by the serverless computing provider. We evaluate the accuracy and applicability of SimFaaS by comparing the prediction results with real-world traces from Amazon AWS Lambda. (More information about the topic> .
More information about the author
The microservice-based architecture – a SOA-inspired principle of dividing systems into components that communicate with each other using language-agnostic APIs – has gained increased popularity in industry. Yet, migrating a monolithic application to microservices is a challenging task. A number of automated microservice extraction techniques have been proposed to help developers with the migration complexity. These techniques, at large, construct a graph-based representation of an application and cluster its elements into service candidates. The techniques vary by their decomposition goals and, subsequently, types of relationships between application elements that they consider – structural, semantic term similarity, and evolutionary – with each technique utilizing a fixed subset and weighting of these relationship types. Motivated to understand how these techniques can better assist practitioners with the microservice extraction process, we performed a multi-method exploratory study with 10 industrial practitioners to investigate (1) the applicability and usefulness of different relationships types during the microservice extraction process and (2) expectations practitioners have for tools utilizing such relationships. In this talk, we discuss the results of our study, which show that practitioners often need a "what-if'' analysis tool that simultaneously considers multiple relationship types during the extraction process and that there is no fixed way to weight these relationships. Our talk also identifies organization- and application-specific considerations that lead practitioners to prefer certain relationship types over others, e.g., the age of the codebase and languages spoken in the organization, and it outlines possible strategies to help developers during the extraction process, e.g., the ability to iteratively filter and customize relationships. (More information about the topic> .
More information about the author
High performance is a critical factor to achieve and maintain the success of a software system. Performance anomalies represent the performance degradation issues (e.g., slowing down in system response times) of software systems at run-time. Performance anomalies can cause a dramatically negative impact on users’ satisfaction. Prior studies propose different approaches to detect anomalies by analyzing execution logs and resource utilization metrics after the anomalies have happened. However, the prior detection approaches cannot predict the anomalies ahead of time; such limitation causes an inevitable delay in taking corrective actions to prevent performance anomalies from happening. We propose an approach that can predict performance anomaliesin software systems and raise anomaly warnings in advance. Our approach uses a Long-Short Term Memory (LSTM) neural network to capture the normal behaviors of a software system. Then, our approach predicts performance anomalies by identifying the early deviations from the captured normal system behaviors. We conduct extensive experiments to evaluate our approach using two real-world software systems (i.e., Elasticsearch and Hadoop). We compare the performance of our approach with two baselines. The first baseline is one state-to-the-art baseline called Unsupervised Behavior Learning (UBL). The second baseline predicts performance anomalies by checking if the resource utilization exceeds pre-defined thresholds. Our results show that our approach can predict various performance anomalies with high precision (i.e., 97-100%) and recall (i.e., 80-100%), while the baselines achieve 25-97% precision and 93-100% recall. For a range of performance anomalies, our approach can achieve sufficient lead times that vary from 20 to 1,403 seconds (i.e., 23.4 minutes). We also demonstrate the ability of our approach to predict the performance anomalies that are caused by real-world performance bugs. For predicting performance anomalies that are caused by real-world performance bugs, our approach achieves 95-100% precision and 87-100% recall, while the baselines achieve 49-83% precision and 100% recall. The obtained results show that our approach outperforms the existing anomaly prediction approaches and is able to predict performance anomalies in real-world systems. (More information about the topic> .
More information about the author
Context: Changing a software application with many build-time configuration settings may introduce unexpected side-effects. For example, a change intended to be specific to a platform (e.g., Windows) or product configuration (e.g., community editions) might impact other platforms or configurations. Moreover, a change intended to apply to a set of platforms or configurations may be unintentionally limited to a subset. Indeed, understanding the exposure of source code changes is an important risk mitigation step in change-based development approaches. Objective: In this experiment, we seek to evaluate DiPiDi, a prototype implementation of our approach to assess the exposure of source code changes by statically analyzing build specifications. We focus our evaluation on the effectiveness and efficiency of developers when assessing the exposure of source code changes. Method: We will measure the effectiveness and efficiency of developers when performing five tasks in which they must identify the deliverable(s) and conditions under which a change will propagate. We will assign participants into three groups: without explicit tool support, supported by existing impact analysis tools, and supported by DiPiDi. (More information about the topic> .
More information about the author
A common strategy for modernizing legacy systems is to migrate them to service-oriented architecture (SOA). A key step in the migration process is the identification of reusable functionalities in the system that qualify as candidate services in the target architecture. We propose ServiceMiner, a bottom-up service identification approach that relies on source code analysis, because other sources of information may be unavailable or out of sync with the actual code. Our bottom-up, code-based approach uses service-type specific functional-clustering criteria. We use a categorization of service types that builds on published service taxonomies and describes the code-level patterns characterizing types of services. We evaluate ServiceMiner on an open-source, enterprise-scale legacy ERP system and compare our results to those of state-of-the-art approaches. We show that ServiceMiner automates one of the main labor-intensive steps for migrating legacy systems to SOA and identifies architecturally-significant services. Also, we show that it could be used to assist practitioners in the identification of candidate services in existing systems and thus to support the migration process of legacy systems to SOA. .
Inversion of control is the standard way to design interactive software. However it leads to designs in which state information is buried and scattered, resulting in designs that are difficult to understand and modify. This talk presents a method for designing and implementing interactive software so that it is structured, simple, and easily modifiable. The method is suitable for languages such as JavaScript that support lambda expressions and closures. (More information about the topic> .
More information about the author
Two similar code segments, or clones, forma clone pair within a software system. The changes to the clones over time create a clone evolution history. Late propagation is a specific pattern of clone evolution. In late propagation, one clone in the clone pair is modified, causing the clone pair to become inconsistent. The code segments are then re-synchronized in a later revision. Existing work has established late propagation as a clone evolution pattern, and suggested that the pattern is related to a high number of faults. In this chapter, we replicate and extend the work by Barbour et al.[1] by examining the characteristics of late propagation in 10 long-lived open-source software systems using the iClones clone detection tool. We identify eight types of late propagation and investigate their fault-proneness. Our results confirm that late propagation is the more harmful clone evolution pattern and that some specific cases of late propagations are more harmful than others. We trained machine learning models using 18 clone evolution related features to predict the evolution of late propagation and achieved high precision within the range of 0.91 to 0.94 and AUC within the range of 0.87 to 0.91. .
More information about the author
A decade after its first release, the Go language has become a major programming language in the development landscape. While praised for its clean syntax and C-like performance, Go also contains a strong static type-system that prevents arbitrary type casting and memory access, making the language type-safe by design. However, to give developers the possibility of implementing low-level code, Go ships with a special package called unsafe that offers developers a way around the type safety of Go programs. The package gives greater flexibility to developers but comes at a higher risk of runtime errors, chances of non-portability, and the loss of compatibility guarantees for future versions of Go. In this talk, I will present the first large-scale study on the practice of breaking type safety in 2,438 popular Go projects. We investigate the prevalence of unsafe code, what developers aim to achieve by breaking type safety, and evaluate some of the real risks projects that use the unsafe package are subjected to. Finally, I will also present how our findings have inspired the maintainers of the Go programming language at making the language safer for developers. (More information about the topic> .
Submissions are already closed. The next call for submissions will be for the Fall 2021 meeting
CSER does not publish proceedings in order to keep presentations informal and speculative.
Ottawa is (as you all know) the capital of Canada. Carleton University is a short taxi-ride from the airport, and is on the O-Train Line 2, providing quick access to downtown hotels. There are also many hotels near the airport.
Registration is online at this Google Forms CSER Sprng 2021 registration link. It will only be active until about 8 a.m. on May 14th, since the organizers will be preparing to start the meeting and will not be able to respond to new registrations after that time. You will be asked to provide your name, email address, position, and university or company. Registered attendees will be sent a Zoom link to attend the meeting. Please register by May 13th at noon to guarantee a spot. Feel free to invite colleagues, but ask them to register here; please don't send them the Zoom link you would have been given.
{kind=link}
{kind=link}
{kind=link}